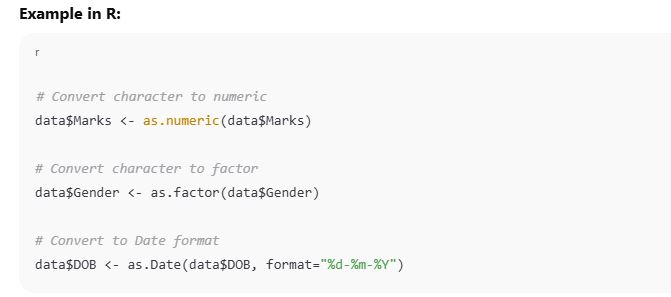





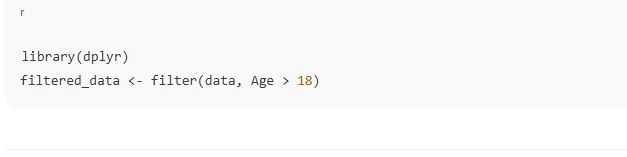














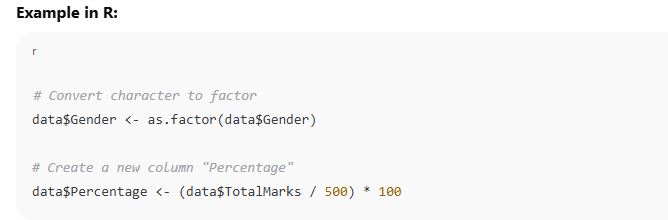












Data type conversion is the process of changing a variable from one data type to another (e.g., from character to numeric).
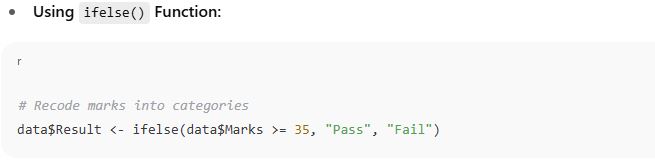
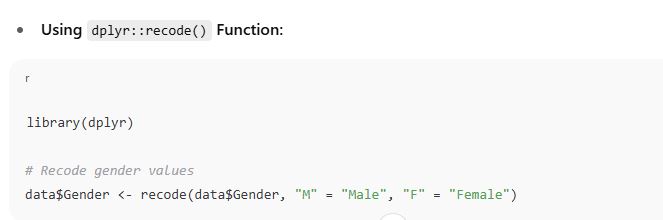
Recoding variables means modifying the values of variables — for example, changing categories or grouping values for better analysis. Both tasks are essential in preparing data for analysis and visualization.

In any dataset, each column or variable has a specific data type such as:
Numeric (e.g., 25, 99.5)
Character (e.g., “Yes”, “No”)
Factor (for categorical data)
Date/Time
Sometimes, we need to change a column’s type for proper analysis or visualization. This is known as data type conversion or type casting.

To perform calculations (e.g., converting strings to numbers)
To format data correctly (e.g., treating text as factors for categories)
To avoid errors during analysis or visualization